Text, Audio, Art, Metadata: We Built an Autonomous Media Pipeline in 8 Weeks
Input goes in. Published media comes out: text, audio, art, metadata. The pipeline runs autonomously, but humans can step in at any point.
That's what we built. Not a fully automated black box, but an autonomous system with human oversight built in. The pipeline asks for help when it needs it. Operators can patch, review, and idempotently restart any stage.
This is the story of how we did it in 8 weeks. Here's what we learned.
Five constraints, eight weeks
The project came with constraints that shaped every decision:
Autonomous by default. The pipeline runs end-to-end without requiring human intervention. But when it hits something it can't handle, it asks for help. Humans can review, patch, and restart any stage. Autonomy with oversight, not a black box.
Multi-modal output. Not just text. Each piece needs generated audio, generated art, and structured metadata. Four different AI systems, coordinated.
Scale. Not one piece at a time. Batches of 100+, processed in parallel, with failures isolated so one bad generation doesn't kill the batch.
Quality bar. Output has to feel crafted. Generic AI slop won't cut it. The system needs domain knowledge, style guidelines, and quality gates.
Eight weeks. From kickoff to users consuming published output.
These constraints weren't obstacles. They were the design spec.
The architecture that emerged
We didn't start with a grand architecture. We started with a question: how do you make an LLM generate complete, high-quality long-form output? Not a 500-word sketch. 5,000+ words that hold together.
The answer: you don't ask once. You orchestrate.
The agent pattern
The core is an autonomous agent running an observe-reason-act-reflect loop:
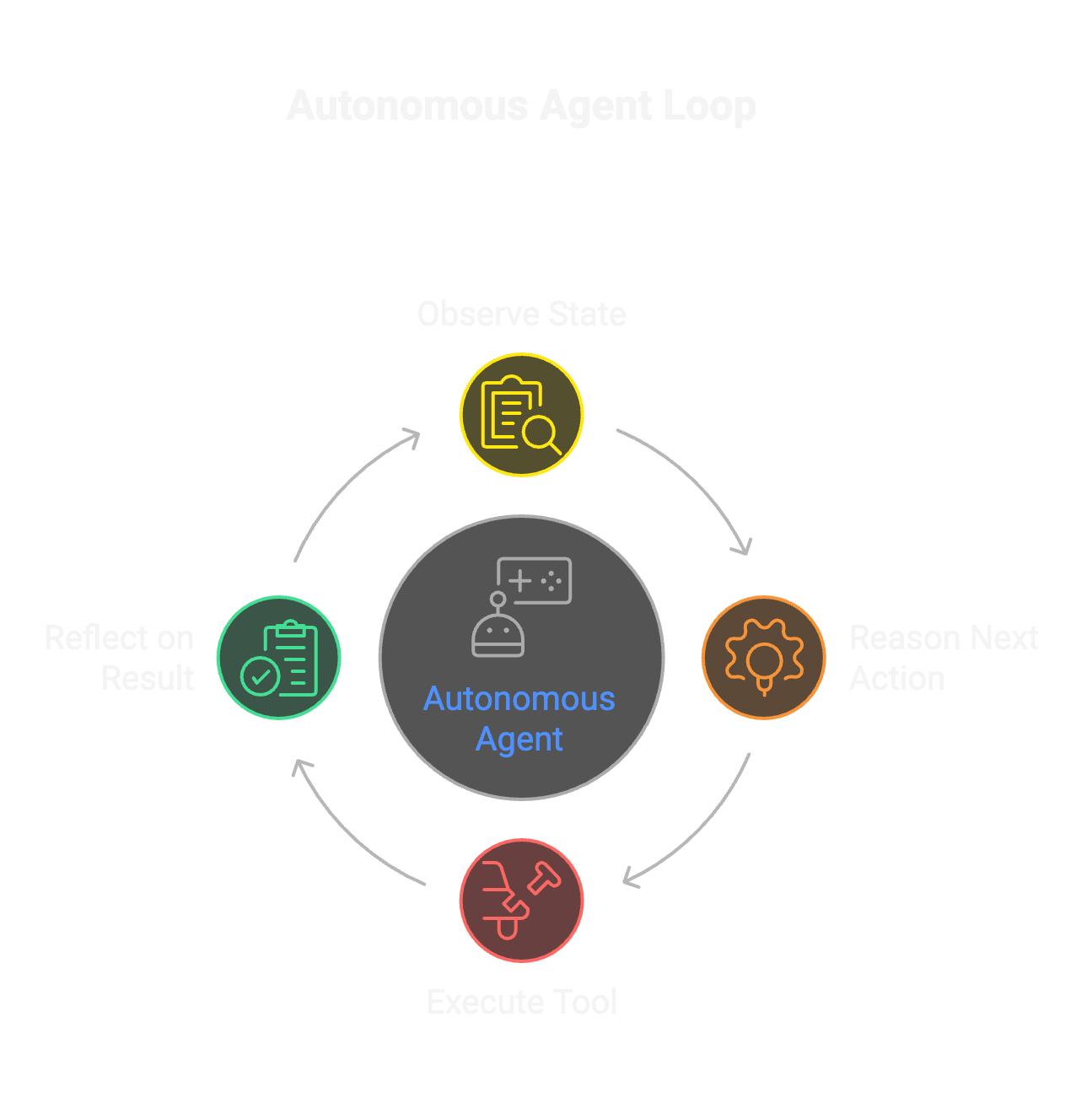
The agent observes its state: Do I have source material loaded? An outline? A draft? How does current output score against quality criteria?
Based on observation, it reasons about what to do next. Load context. Create structure. Generate content. Evaluate it. Revise if needed. The LLM decides, not hardcoded logic.
Then it acts by calling a tool, reflects on the result, and loops.
Tools, not prompts
The agent orchestrates a set of independent tools. Each tool does one thing. The agent decides which to call and in what order. The tools don't know about each other.
This matters because it makes the system:
- •Testable: Each tool can be tested in isolation
- •Replaceable: Swap implementations without touching orchestration
- •Debuggable: See exactly which tool produced which result
Knowledge base as source of truth
All domain knowledge lives in markdown files. Not in prompts. Not in code. In readable, version-controlled documents that the LLM interprets directly.
Adding a new domain or variant means adding a file. No code changes. No prompt surgery. No deployment.
The practical impact: domain experts can improve the system by editing markdown. They don't need to understand Python or prompt engineering.
Decisions that defined the project
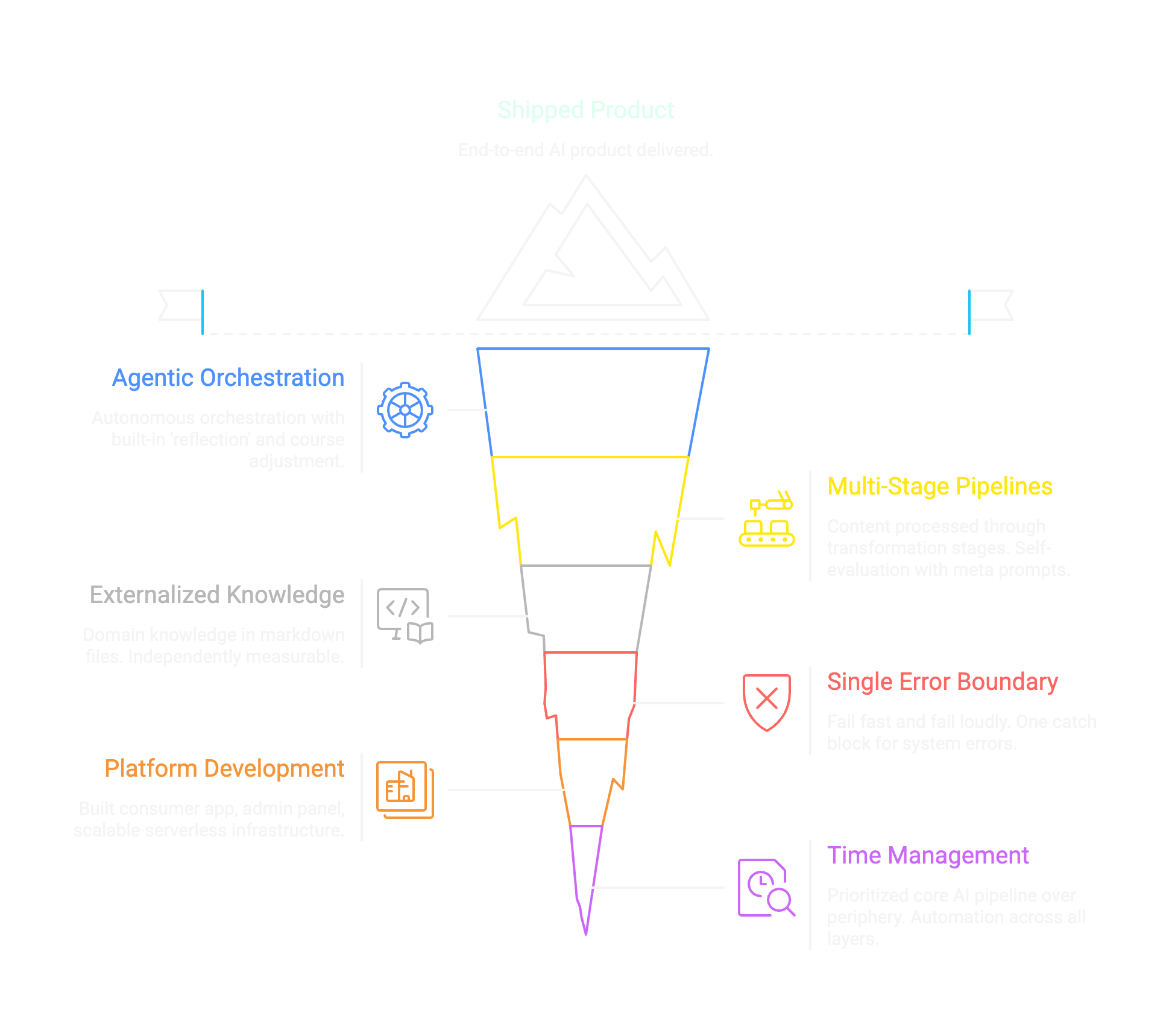
Single error boundary
Conventional wisdom says fail gracefully. Catch exceptions. Provide fallbacks. Degrade elegantly.
We did the opposite. One catch block in the entire system, at the agent's core loop. Everything else raises.
Why? In active development of AI systems, visibility beats resilience. When something breaks (and with LLMs, things break in surprising ways), you need to see exactly what happened. Not a sanitized error message. The full stack trace.
We'll add graceful degradation later, when we understand the failure modes. Right now, loud failures are features.
Externalized domain knowledge
The alternative was encoding domain knowledge in prompts. Repeating and varying context across different prompt files.
That's a trap. Prompts become enormous. Knowledge scatters. Adding variants means editing code.
Instead: markdown files the LLM reads directly. The knowledge base teaches the domain. The prompts ask for specific outputs. Separate concerns.
Build the platform, not just the AI
We could have stopped at generation. Input in, media out. Impressive demo.
But AI without distribution is a demo. We wanted users consuming published output.
So we built the platform: consumer apps, admin panels, content management, delivery infrastructure. All of it.
The last 20% of the work (distribution, admin tools, user management) is what separates demos from products.
Where we spent time vs. where we saved time
Time well spent
Multi-stage media pipeline. Text generation is one thing. Coordinating text → audio → art → metadata is another. Long content causes API timeouts. Different modalities have different failure modes. We built chunking, parallel processing, and per-stage error handling. This took real engineering time. Worth it.
Idempotent batch processing. AI operations are expensive. Re-running a failed batch shouldn't regenerate completed items. We built per-stage completion tracking. Safe restarts. No wasted API calls.
State management. The agent needs to know: What version am I on? What did the last evaluation say? Am I stuck in a loop? We built comprehensive state tracking with versioning, evaluation history, and loop detection. The agent can even abort itself when it detects unproductive patterns.
Time saved
No custom auth. Managed auth services. Done in a day. Would have taken weeks to build properly.
No custom infrastructure. Serverless compute, managed databases, cloud storage. All managed. All scales automatically.
No infrastructure management. We didn't provision servers. We didn't configure load balancers. We didn't set up monitoring dashboards. Cloud providers handle it.
Built (Time Well Spent)
- • Media Pipeline
- • Batch Processing
- • State Management
- • Agent Logic
Bought (Time Saved)
- • Authentication
- • Infrastructure
- • Hosting
- • Storage
The pattern: build what's core to your value (the AI pipeline, the agent logic). Buy everything else.
What we'd do differently
Start with the consumer experience earlier. We built generation first, platform second. It worked, but we discovered UX requirements late. Building consumer-out might have surfaced these sooner.
More aggressive prompt externalization from day one. We knew prompts should be in files, not code. But early prototyping had inline prompts that we had to extract later. Starting with the rule "every prompt is a file, no exceptions" would have saved refactoring.
Plan for content operations alongside tech. Generating media is technical. Curating, managing quality, deciding what to publish: that's operations. We built admin tools reactively. Planning for content operations from the start would have shaped the tools better.
The real lesson
8 weeks isn't the story. Shipping is.
Enterprise quality doesn't require enterprise timelines. It requires:
- •Clear scope: We knew what "done" looked like
- •Ruthless prioritization: Build core, buy periphery
- •Working end-to-end early: A thin slice through the whole system beats a polished fragment
- •Accepting imperfection: Ship, then improve
The difference between a demo and a product is the last 20%: the media pipeline that makes output consumable, the admin panel that makes content manageable, the infrastructure that makes it reliable.
We built both systems (generation and distribution) because one without the other is incomplete. AI that produces output nobody consumes is a research project. AI integrated into a product people use is valuable.
Have an AI project stuck between demo and production? That's exactly where we work. Let's talk.