Most AI Failures Aren't Model Failures. They're Data Shape Failures.
Traditional data systems were built for humans. AI agents need something different: a machine-facing layer designed for reasoning and action.
When an AI agent makes a bad decision, the instinct is to blame the model. But in our experience building enterprise AI systems, the model is rarely the problem. The data is.
Not missing data. Not dirty data. The shape of the data. The model doesn't see clean, structured, contextualized business state. It sees fragmented tables, ambiguous fields, and disconnected systems. And then it hallucinates.
Most AI failures in enterprises are data shape failures, not model failures.
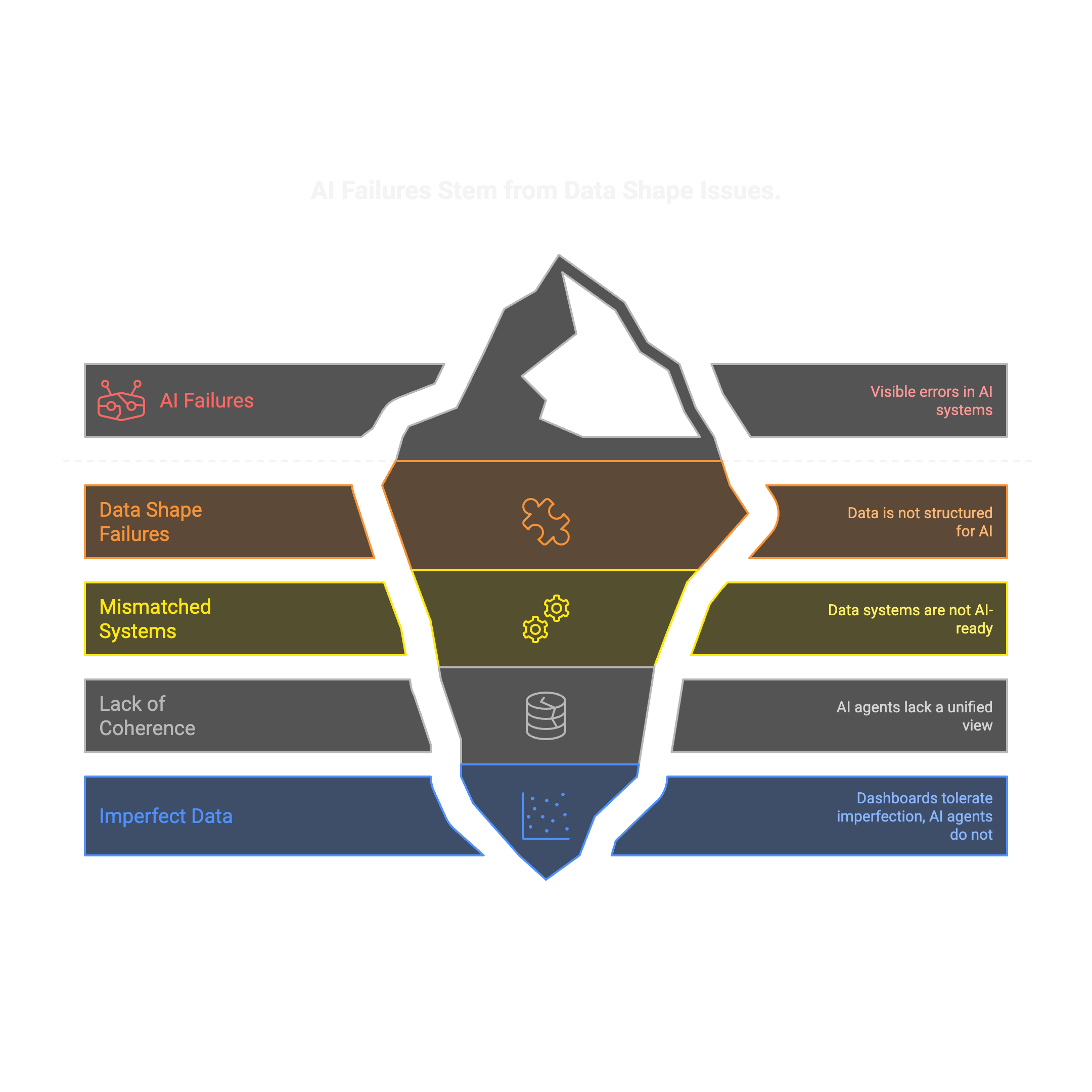
The mismatch between data systems and AI agents
Traditional enterprise data systems were designed for a specific purpose: reporting, dashboards, human analysis. They answer questions like "What happened last quarter?" and "How are we trending?"
AI agents are fundamentally different. They reason over current state. They combine structured and unstructured data. They trigger actions. They must operate safely under permissions and constraints.
A data warehouse optimizes for analytical queries across historical data. A data lake stores raw files for batch processing. Neither is optimized for what an AI agent actually needs: a coherent view of current business state, explicit relationships, and governed interfaces for taking action.
Dashboards tolerate imperfection. Autonomous agents do not. If a dashboard is slightly wrong, it's inconvenient. If an AI agent takes the wrong action, it creates financial, legal, or operational risk.
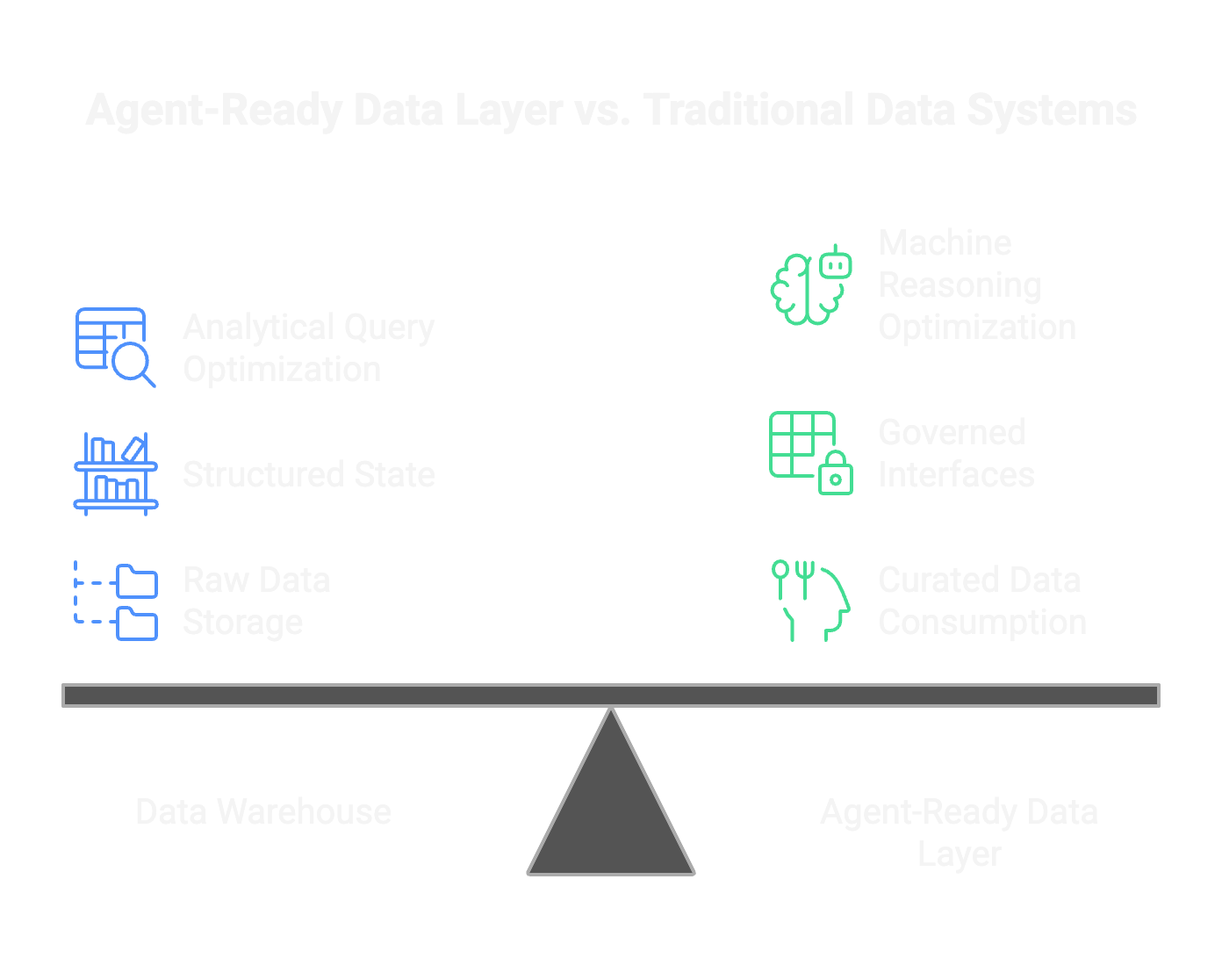
What AI agents actually need
We call this an Agent-Ready Data Layer: a machine-facing composition of data structures between your operational systems and your AI agents. Not a single database. A layer that presents:
- Clean business entities (not raw tables)
- Structured state (not scattered across systems)
- Explicit relationships (not implicit foreign keys)
- Governed interfaces (not open access)
- Retrievable knowledge (not buried in documents)
The key word is composed. This isn't one technology. It's a composition of the right data structures for the job.
Four components of an agent-ready data layer
In practice, this layer has four distinct components. Each serves a specific purpose.
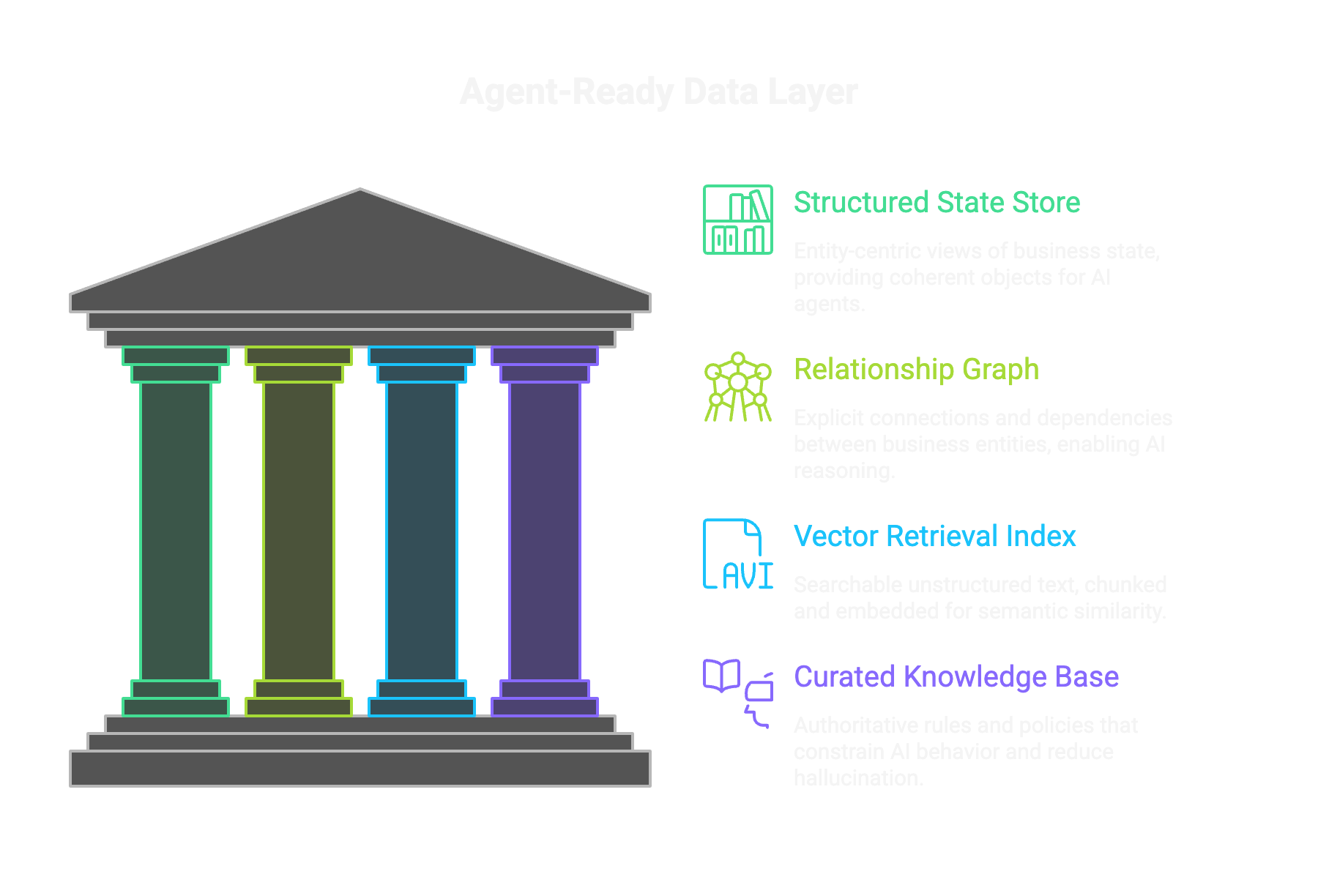
1. Structured State Store
Entity-centric views of business state. Not tables with cryptic columns. Coherent objects like CustomerProfile that bundle identity, risk score, contract status, and billing health into one retrievable unit.
The schema is stable. Context is pre-aggregated. Permissions are baked in. When an agent asks "what's the state of this customer?", it gets a complete, permission-scoped answer in one call.
2. Relationship Graph
Connections and dependencies made explicit. Customer → Account → Contract → Clause → Obligation. Not buried in JOIN statements or foreign key relationships. A traversable graph that helps agents reason over constraints.
When an agent needs to know if a customer is eligible for a discount, it can walk the graph from customer to contract to specific clause. The relationship is explicit, not inferred.
3. Vector Retrieval Index
Unstructured text made searchable: policies, emails, meeting notes, documentation. Chunked, embedded, retrievable by semantic similarity. This is your RAG layer.
The key is curation. Not everything goes in. The documents that inform decisions get indexed. The rest stays out. Quality over quantity.
4. Curated Knowledge Base
Authoritative rules that constrain behavior: pricing policies, compliance rules, decision frameworks. Not generated by AI. Written by humans. Curated and maintained.
This is what reduces hallucination. When an agent needs to apply a pricing rule, it retrieves the rule from the knowledge base. It doesn't guess. It doesn't make assumptions. It follows documented policy.
With and without: a contract renewal example
Consider an AI agent handling contract renewal. Two scenarios:
Without an agent-ready data layer
- Agent queries CRM API. Gets flat JSON.
- Separately queries billing system.
- Searches email archive for context.
- No link between contract terms and billing data.
- Agent hallucinates a discount the customer isn't eligible for.
- Sends wrong renewal offer.
Result: Financial and legal risk.
With an agent-ready data layer
- Agent requests CustomerProfile entity.
- Gets contract status, risk score, billing health (pre-aggregated).
- Graph query: Contract → Clauses → renewal terms + discount eligibility.
- Vector retrieval: relevant policy documents.
- Knowledge base: pricing rules applied.
- Agent sends correct, compliant offer.
Result: Accurate, governed, auditable.
The difference isn't the model. It's whether the model sees structured business state or fragmented system outputs.
What makes data agent-ready
Six characteristics distinguish agent-ready data from traditional enterprise data:
- Entity-centric (not just table-centric)
- Context-aggregated (not fragmented across systems)
- Explicit semantics (not ambiguous field names)
- Real-time or near real-time (not batch-only)
- Evaluatable and logged (every query traceable)
- Permission-controlled (scoped to agent role)
What this isn't
Three common misconceptions:
"It's just a data warehouse." Warehouses optimize for analytical queries. This optimizes for machine reasoning and action. Different workload. Different design.
"It's just a vector database." Vector search is one component. Without structured state and governed interfaces, you have semantic search. Not an operational layer for agents.
"We already have a data lake." Data lakes store raw data. This curates, structures, and governs data specifically for agent consumption. Storage is not the same as readiness.
The Bottom Line
This is the machine-facing equivalent of the data warehouse. Data warehouses were designed to report what happened. An agent-ready data layer is designed to help AI systems reason about what should happen next.
If your AI agents are failing, look at the data shape before you blame the model.